Wikipedia definition: Instruction-level parallelism (ILP) is a measure of how many of the instructions in a computer program can be executed simultaneously.
Instruction refers to machine instruction. Two instructions can be run simultaneously (or in any order with no difference in the run outcome) if and only if they are independent.
Two instructions are independent if and only if they have no data, name or control dependencies.
There is a data dependency between two instructions if the first one produces at least one value consumed by the second one (RAW or Read After Write dependency). This value can transit in a register (written then read) or in a memory location (stored then loaded).
There is a name dependency between two instructions if they use the same register or memory location but have no data dependency. Either they both write to the same destination (WAW or Write After Write dependency) or the first one reads/loads and the second one writes/stores the same location (WAR or Write After Read dependency).
There is a control dependency between two instructions if the first one computes a value conditioning the execution of the second one.
Quantifying ILP
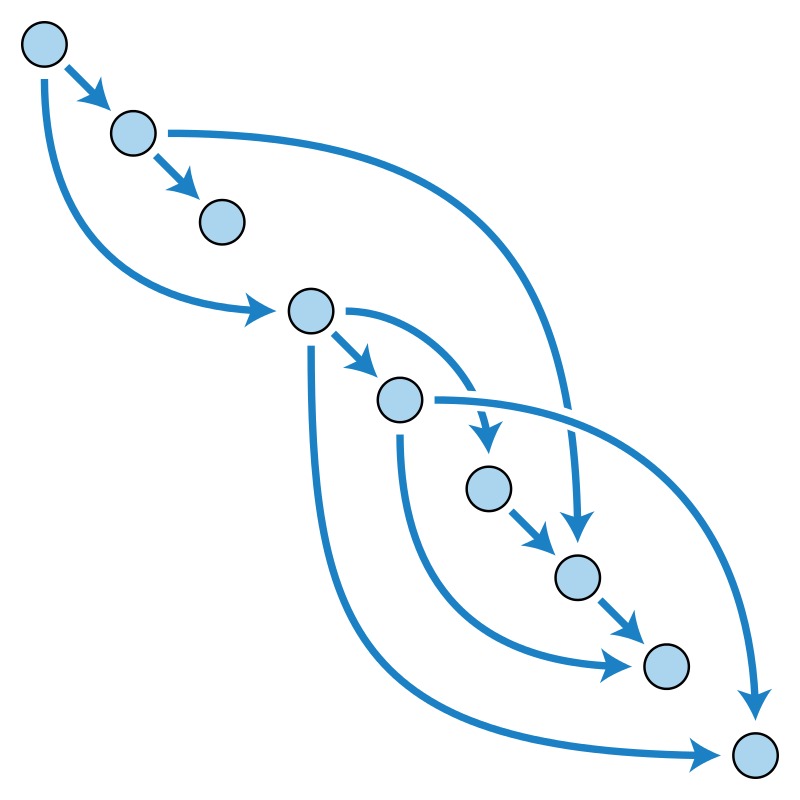
The set of instructions to be run can be partially ordered from its dependencies, resulting in a DAG (Direct Acyclic Graph) showing the topological ordering of the run.
ILP can be quantified as the number of nodes in the graph divided by the length of the longest path.
The graph on the figure has 9 nodes and the longest path has length 5 (nodes 1, 4, 6, 7, 8), hence ILP is 1.8.
The average ILP of programs is low (less than 2).
Increasing local ILP
ILP can be increased either by increasing the number of nodes (computing more) or decreasing the length of the longest paths (eliminating dependencies).
Computing more is related to the software, for example by applying the program to a larger input.
Decreasing the length of the longest paths is both related to software and hardware. A parallel algorithm has less RAW dependencies than a serial one. This is software related. But also, WAR and WAW dependencies can be removed through renaming and control dependencies can be removed through branch prediction. This is hardware related.
ILP can be subdivided into local ILP and global ILP.
Local ILP is the ILP that can be found in a small window (i.e. less than a thousand) of contiguous instructions in a run trace.
Global ILP is the ILP that can be found arbitrarily far out of the local window. For example, two independent loops, one in a starting portion of the run and the other in an ending part, may be separated by billions of instructions in the run trace but still may present some independencies which are part of the global ILP.
Local ILP can be slightly increased (up to 6) through register renaming and branch prediction.
Local ILP can also be increased through value prediction. Correctly predicting a value v removes any RAW dependency for instructions reading v with the computation of v.
Increasing global ILP
Global ILP refers to the ILP that can be found further than the size of the local window (i.e. further than a thousand of instructions).
Global ILP is very low (no better than local ILP), not because of the computation itself, but because of stack manipulations.
When a function is entered, some registers are saved on the stack, including the return address. They are restored upon return. Local variables are allocated on stack locations which may be shared by other function calls. This creates a lot of parasitic dependencies which impact global ILP.
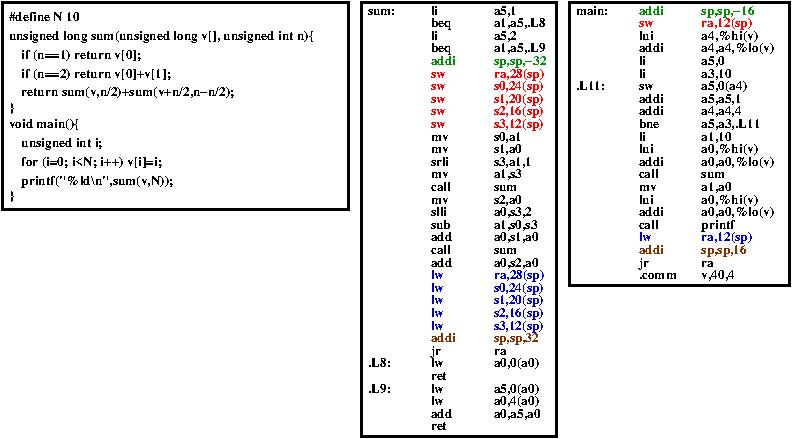
On the next figure, in function main register ra and in function sum registers ra and s0 to s3 are saved on the stack (in red). They are restored before return (in blue). To provide space on the stack, the stack pointer is updated (in green to allocate space, in brown to free space).
This creates dependencies between the entrance and the exit of the function call.
There are memory RAW dependencies (a lw load instruction depends on the matching sw store instruction). There are register RAW, WAW and WAR dependencies on the sp register.
There is an implicit RAW dependency on the ra register between the call instruction and its matching return (jr ra or ret).
There are also dependencies between a returning function and the next call (next addi sp,sp,-k depends (RAW, WAW and WAR) on the previous addi sp,sp,k').
Last, there are memory dependencies (RAW, WAW, WAR) between two recursive calls at the same hierarchical level (i.e. the stack savings in sum(v+n/2,n-n/2) depend on the stack savings/restorations in sum(v,n/2) as they use the same stack locations).
The successive calls form a chain and the resulting ILP is the average of the ILPs of the calls.
For N=10, the chain of successive function calls has length 23 hence the ILP cannot be greater than 237/23, i.e. 10 (237 is the total number of instructions run, excluding printf).
To increase the global ILP, the microarchitect must eliminate the stack. If function calls can be made independent, i.e. avoid saving/restoring PC and other registers to the stack, their respective local ILPs can be added to the final ILP.
This assumes that each independent function call works on a private set of data, i.e. private registers and private local memory.
On the next code (bottom-up iterative rather than top-down recursive), it is assumed that the different calls to sum2 are distributed on successive cores (OpenMP pragma parallel for).
They use disjoint local memory (no stack) and different registers (which is equivalent to a full renaming). They load from and store to disjoint parts of the global array a.
The ILP is the sum of the sum2 function call ILPs, i.e. proportional to SIZE.
The parallelization of a sum
#define SIZE ...
int a[SIZE]={...};
void sum2(int i, int j){
a[j]+=a[j+i];
}
void sum1(int i){
int j;
#pragma omp parallel for
for (j=0; j<SIZE; j+=2*i) sum2(i, j);
}
void main(){
int i;
for (i=1; i<SIZE; i*=2) sum1(i);
}