Hardware techniques to exploit ILP
Exploiting the local ILP
The processor provides slots to host the local window from which the local ILP is exploited.
In a pipeline, each stage represents a slot in which an instruction resides. An n stage pipeline may host up to n dynamically consecutive instructions (typically, a pipeline hosts between one and a few tens of instructions).
Hardware techniques like bypassing and branch delay slots are used to help filling the pipeline.
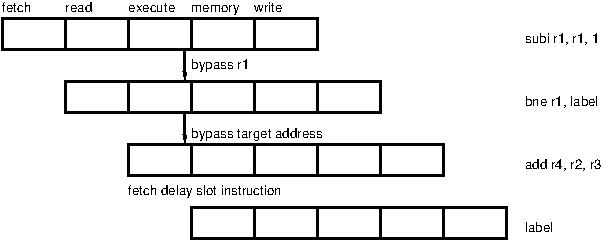
Bypass serves to shorten the delay in a RAW dependency. The value to be transmitted is forwarded to the reading instruction as soon as it is computed rather than after it has been written (on the next figure, value r1-1 is forwarded to the bne instruction).
Branch delay serves to hide the latency of a computed control flow instruction. While the control flow target address is computed, the following instructions are fetched and inserted in the pipeline to be run. They are semantically part of the computation preceding the branch even though they statically follow it (on the next figure, the add instruction is run whether the branch is taken or not).
To increase the size of the local window, either superscalar or VLIW or EPIC processors are used.
A superscalar processor offers multiple identical and generic pipelines. Each pipeline can handle any instruction.
A VLIW (Very Large Instruction Word) processor offers multiple specific pipelines. Each pipeline can handle a subset of the instructions, e.g. an integer computation pipeline, a memory access pipeline and a branch pipeline. The compiler packs multiple instructions into a large word adapted to the set of available pipelines.
An EPIC (Explicitely Parallel Instruction set Computer) processor is a VLIW processor with a large set of registers to allow static register renaming. The static renaming increases the local ILP by removing some name dependencies, which helps the compiler to find more instructions to fill the words.

To hide long latencies (e.g. a division or a memory access with multi-level cache misses) the processor may run instructions out-of-order.
An out-of-order processor issues instructions according to the availability of their sources and operators. For example, while a memory load is in flight, instructions which are independent of the loaded value can be issued even though they follow the load in the dynamic trace.
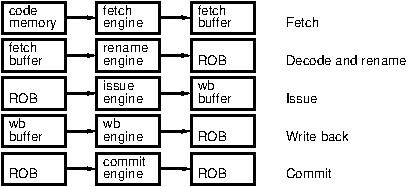
The processor is organized around a set of concurrent engines rather than a pipeline.
The fetch engine reads instructions in-order and saves them in a fetch buffer.
The decode and rename engine reads in-order the instructions saved by the fetch engine. It eliminates name dependencies and detects RAW dependencies through register renaming. The needed operator is identified from the instruction decoding. The renamed instructions are saved in a ReOrder Buffer (ROB) which represents the window from which local ILP can be exploited.
The issue engine selects ready renamed instructions, i.e. which sources and needed operator are all available. The operation may take multiple cycles. When the result is computed, it is written to a write-back buffer and the instructions in the ROB waiting for the written value are notified. Waiting instructions may be issued out-of-order.
The write-back engine selects write-back buffer entries to write their result to the destination register file. Terminated instructions are marked in the ROB. Instructions may terminate out-of-order.
The commit engine removes the terminated instructions from the ROB in-order.