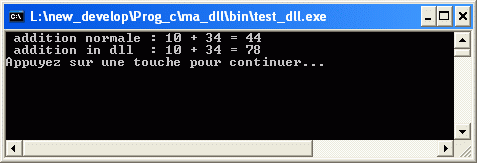
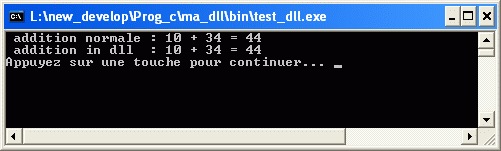
/** @file litreel.c miscellaneous functions incl. reading with parsing */
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
// define boundaries for all tables in the model
// ---------------------------------------------
#ifndef _BOUNDARIES_
# define _BOUNDARIES_
# define MAXCAP 50 /**< max lenght of a caption */
# define MAXLINE 255 /**< max lenght of line */
# define NAMELENGTH 64 /**< fixed name length */
#endif /* _BOUNDARIES_ */
/** removes spaces at both ends of a string
******************************************
* @param input : chaine de caracteres à traiter
*/
void trimboth(char* input) {
char* pos; // current position non-space-char
char* pos2; // current position original string
char* beg; // pointer to the beginning of non-space char
char* end; // pointer to the end of non-space char
// find actual start of line
beg = input;
while isspace((unsigned char)*beg)) {
++beg;
}
// find last non space character (and replace by /0)
//
end = input + strlen(input)-1;
while (end > beg && isspace((unsigned char)*end)) {
*end = '\0'; // replace space by '/0' (= right trim)
end--;
}
// Move if needed.
//
if (beg == input) return; // no space at the line start (we are done)
pos = beg;
pos2 = input;
while (pos <= end) {
*pos2 = *pos; // move characters one by one
pos++;
pos2++;
}
while (pos2 <= end) {
*pos2 = '\0'; // pad with '/0'
pos2++;
}
}
/** replace all character oldc by newc
*************************************
* @param str : string to modify
* @param oldc : character to replace
* @param newc : character to set
* @return number or replaced characters
*/
int strrepl(char *str, int oldc, int newc){
int lindex = 0;
int i = 0;
if (oldc == '\0') return 0; // Do not replace NULL character !
while(str[lindex] != '\0')) { // Check until a char 13 is found
if (str[lindex] == oldc) {
str[lindex] = newc;
++i;
}
++lindex;
}
return i;
}
/* Read a line and skips non meaning lines
******************************************
*
* non meaning lines are empty lines or line containing only spaces, tab (see isspace function)\n
* or\n
* comment lines, starting by # or !
*/
long read_skip(FILE* lec, FILE* imp, char* ligne) {
int line_OK = false; // found a line to analyse
long ErrCode = EXIT_SUCCESS; // variable to report error codes
do {
if (fgets(ligne, MAXLINE, lec) == NULL) { // Read & check if end of file is reached
if (feof(lec) != 0) {
ErrCode = EOF; // dans <stdio.h> vaut -1
} else {
ErrCode = READ_ERROR; // defined in util.h
}
return ErrCode;
}
trimboth(ligne); // compulsory to have a true empty line
// the trailing '\n' was removed
line_OK = true;
if (strnlen_s(ligne, MAXLINE) == 0) { // Empty line : not OK
line_OK = false;
} else if ((ligne[0] == '#') || (ligne[0] == '!')) { // Comment line : not OK
line_OK = false;
if ((ligne[1] == '>') && (debug >= 2)) { // print this comment in the trace file
ligne[0] = '>';
fprintf(imp,"\t%s\n",ligne);
} else if (strstr(ligne, "#N/A") != 0) { // special case, Excel error reporting can be confused with comment
ErrCode = EXCEL_NAN; // defined in util.h
return ErrCode;
}
}
} while (!line_OK); // loop until not empty and not a comment
return ErrCode;
}
/** splits a line into data and caption (attention internal of util.c)
**************************************
*
* @param ligne : input string to split
* @param data_txt : return string containing data part
* @param caption : return string containing caption part
*/
long split_line(char* ligne, char* data_txt, char* caption) {
char* legende; // label as read
char* donnee; // data part (as string)
long ErrCode = EXIT_SUCCESS; // variable to report error codes
memset(data_txt,'\0',MAXLINE); // fill data_txt with NULL character
memset(caption,'\0',MAXLINE); // fill caption with NULL character
donnee = ligne;
legende = strpbrk(ligne,"!#");
if (legende != NULL)> {
legende++;
ErrCode = strncpy_s(caption, MAXLINE, legende,_TRUNCATE);
if (ErrCode != EXIT_SUCCESS) return ErrCode; // EINVAL (zero length legende ou caption) ; ERANGE when MAXLINE=NULL defined in <errno.h>
ErrCode = strncpy_s(data_txt, MAXLINE, donnee,strlen(ligne)-strlen(caption)-1); // ne pas mettre _TRUNCATE
} else {
ErrCode = strncpy_s(caption, MAXLINE, "without caption",_TRUNCATE);
if (ErrCode != EXIT_SUCCESS) return ErrCode; // pb dans la copie
ErrCode = strncpy_s(data_txt, MAXLINE, ligne,_TRUNCATE);
}
return ErrCode; // returns an error code
}
/** Fill the end of caption with dots
************************************
*/
void pad_caption(char* caption) {
char* end; // pointer to the end of non-space char
char* pos2; // current position original string
int leglen;
leglen = strlen(caption);
if (leglen >= MAXCAP) return; // long caption = nothing to fill
pos2 = caption + leglen;
end = caption + + MAXCAP - 1;
while (pos2 < end) {
*pos2 = '.'; // pad with '.'
pos2++;
}
*pos2 = '\0'; // add final NULL
}
/** Reads a double escaping comments and parsing legend
******************************************************
* @param imp : file to trace reading
* @param lec : file to read
* the line to read has the form \n
* data ! label
* the following output will be send to imp stream
* caption........: data
* or
* - caption......: data
* where caption is a formated label (50 char max, dot are append at the end to reach 50 char)
*
* comments are lines where first nonblank charater is '#' or '!'
* if a comment starts with '#>' or '!>' it is printed in imp
*
* @param imp : file to trace reading
* @param lec : file to read
* @param[out] data : double to read
* @return error code
*/
long litreel(FILE* lec, FILE* imp, double* data) {
char* ligne = NULL; // string to read
char* caption = NULL;
char* data_txt = NULL; // data to read as a string
char* err;
// char er_msg[MAXLINE]; // Error message
char* er_msg = NULL; // Error message (not allocated)
long ErrCode = EXIT_SUCCESS; // variable to report error codes
long ErrSever; // Error severity
ligne = (char*)calloc(MAXLINE,sizeof(char));
// memset(ligne,'\0',MAXLINE); // fills with zeros
caption = (char*)calloc(MAXLINE,sizeof(char));
data_txt = (char*)calloc(MAXLINE,sizeof(char));
er_msg = (char*)calloc(MAXLINE,sizeof(char));
/* Read string buffer while skipping comments
------------------------------------------ */
ErrCode = read_skip(lec, imp, ligne);
if (ErrCode != EXIT_SUCCESS) {
ErrSever = FATAL; // stop run
if (ErrCode == EOF) {
alarme(ErrCode, imp, ErrSever, "litreel", "End of file while reading");
} else if (ErrCode == EXCEL_NAN) {
if(debug >=1) fprintf(imp,"%s\n",ligne);
alarme(ErrCode, imp, ErrSever, "litreel", "Excel Not a Number in the line");
} else {
alarme(ErrCode, imp, ErrSever, "litreel", "IO error while reading file");
}
}
/* Split string buffer into data and label
--------------------------------------- */
ErrCode = split_line(ligne, data_txt, caption);
trimboth(data_txt);
strrepl(data_txt,',','.'); // replace coma by dot (french Excel !)
trimboth(caption);
/* decode data part
----------------------- */
if ((data_txt[0] == '*') && (data_txt[1] == '*')) { // '**' = asks data on the standard input
fprintf(stdout, "(enter) %s :",caption);
// fgets(data_txt, MAXLINE, stdin);
if( fgets(data_txt, MAXLINE, stdin) == NULL) {
ErrCode = KEYB_READ;
ErrSever = FATAL; // stop run
alarme(ErrCode, imp, ErrSever, "litreel", "error while entering data in keyboard");
}
}
err = data_txt;
// data = 0.0;
*data = strtod(data_txt,&err);
if (err == data_txt) { // an error occured during conversion
ErrCode = ERANGE; // dans <math.h> = 34
ErrSever = FATAL;
sprintf_s(er_msg, MAXLINE, "error: data is not a valid double \n %s", err);
alarme(ErrCode, imp, ErrSever, "litreel", er_msg);
}
/* print the result in a formatted way "caption......: data"
---------------------------------------------------------- */
pad_caption(caption);
// if(verbo) fprintf(stdout,"%s: %g\n",caption,data);
// if(debug > =2) fprintf(imp,"\t%s: %g\n",caption,data); // for html
if(debug >= 2) fprintf(imp, "- %s: %g\n",caption, *data); // for markdown list
free(er_msg);
free(data_txt);
free(caption);
free(ligne);
return ErrCode;
}
/** reads a long int escaping comments and parsing legend
********************************************************
* @param imp : file to trace reading
* @param lec : file to read
*
* the line to read has the form \n
* data ! caption \n
* the following output will be send to imp stream \n
* \tcaption........: data \n
* or \n
* - caption........: data
* where caption is a formated label (MAXCAP char max, dot are append at the end to reach 50 char)
*
* comments are lines where first nonblank charater is '#' or '!'
* if a comment starts with '#>' or '!>' it is printed in imp
*
* When the line starts by two stars '**', the data is not read from the normal stream but from the keybord (stdin)
*
* @param imp : file to trace reading
* @param lec : file to read
* @param[out] data : integer to read
* @return error code
*/
long int litentier(FILE* lec, FILE* imp, long* data) {
char* ligne = NULL; // string to read
char* caption = NULL;
char* data_txt = NULL; // data to read as a string
char* err;
// char er_msg[MAXLINE]; // Error message
char* er_msg = NULL; // Error message (not allocated)
long ErrCode = EXIT_SUCCESS; // variable to report error codes
long ErrSever; // Error severity
ligne = (char*)calloc(MAXLINE,sizeof(char));
// memset(ligne,'\0',MAXLINE); // fills with zeros
caption = (char*)calloc(MAXLINE,sizeof(char));
data_txt = (char*)calloc(MAXLINE,sizeof(char));
er_msg = (char*)calloc(MAXLINE,sizeof(char));
/* Read string buffer while skipping comments
------------------------------------------ */
ErrCode = read_skip(lec, imp, ligne);
if (ErrCode != EXIT_SUCCESS) {
ErrSever = FATAL; // stop run
if (ErrCode == EOF)> {
alarme(ErrCode, imp, ErrSever, "litentier", "End of file while reading");
} else if (ErrCode == EXCEL_NAN) {
if(debug>=1) fprintf(imp,"%s\n",ligne);
alarme(ErrCode, imp, ErrSever, "litentier", "Excel Not a Number in the line");
} else {
alarme(ErrCode, imp, ErrSever, "litentier", "IO error while reading file");
}
}
/* split string buffer into data and label
--------------------------------------- */
ErrCode = split_line(ligne, data_txt, caption);
/* if (ErrCode != EXIT_SUCCESS) {
ErrSever = FATAL; // stop run
if (ErrCode == EINVAL) {
alarme(ErrCode, imp, ErrSever, "litentier", "data_txt or caption not allocated");
} else if (ErrCode == ERANGE) {
alarme(ErrCode, imp, ErrSever, "litentier", "MAXLINE = 0 !");
}
} */
trimboth(data_txt);
trimboth(caption);
/* decode data part
----------------------- */
if ((data_txt[0] == '*') && (data_txt[1] == '*')) { // '**' = asks data on the standard input
fprintf(stdout,"(enter) %s :",caption);
// fgets(data_txt, MAXLINE, stdin);
if( fgets(data_txt, MAXLINE, stdin) == NULL) {
ErrCode = KEYB_READ;
ErrSever = FATAL; // stop run
alarme(ErrCode, imp, ErrSever, "litentier", "error while entering data in keyboard");
}
}
err = data_txt;
// *data = 0;
*data = strtol(data_txt,&err,10); // 10 means base 10
if (err == data_txt) { // an error occured during conversion
ErrCode = ERANGE;
ErrSever = FATAL;
sprintf_s(er_msg,MAXLINE," %s is not a valid integer \n",err);
alarme(ErrCode, imp, ErrSever, "litentier", er_msg);
}
/* print the result in a formatted way "caption......: data"
---------------------------------------------------------- */
pad_caption(caption);
// if(verbo) fprintf(stdout,"%s: %ld\n",caption,*data);
// if(debug>=2) fprintf(imp,"\t%s: %ld\n",caption,*data); // html
if(debug >= 2) fprintf(imp, "- %s: %ld\n",caption, *data); // for markdown list
free(er_msg);
free(data_txt);
free(caption);
free(ligne);
return ErrCode;
}