dashboard
Deterministic OpenMP Simplifies Parallel Programming
Deterministic OpenMP is a deterministic implementation of an OpenMP subset to run codes on a PISC ISA based manycore processor. A Deterministic OpenMP program is divided at runtime into an ordered set of harts. These harts have an implicit placement on cores related to a referential sequential order. The ordering and the controlled placement of the harts simplifies the producer/consumer software synchronization which is implicit and optimizes the hardware communication delays which are mostly proportional to neighbor core distances.

call_split
PISC Extends RISC to Parallelization
PISC is an extension to RISC Instruction Set Architecture (ISA). It provides machine instructions to fork the computation and send/receive registers to/from neighbor cores. It provides new call/return machine instructions with parallelizing capabilities and synchronized joins.

developer_board
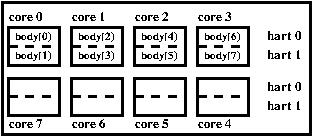
LBP is a Manycore Implementing PISC
LBP is a 64-core processor. The cores are organized on a line topology (no NoC). Each core is as simple as possible to favour a maximum density of cores, i.e. scalar (one scalar instruction fetched, one scalar instruction issued per cycle, no vector unit), multithreaded (4 harts per core), non interruptible and runs out-of-order non speculatively (no branch predictor). Each core has a local instruction memory and a local data memory. The processor provides a shared global memory distributed along the cores (one bank per core). The coherence is ensured by software (through ordered accesses synchronized by the hardware).