LBP performance on a matrix multiplication program
The LBP processor has been tested on a parallelized matrix multiplication program.
A set of 5 versions of the multiplication have been run: base, copy, distributed, d+c (distributed and copy) and tiled.
The "base" version is the classic 3 loops algorithm (parallelized with Deterministic OpenMP).
The "copy" version copies a line of matrix X in the local stack to avoid its multiple accesses.
The "distributed" version distributes each matrix evenly on the memory banks, to avoid the concentration of memory accesses on the same banks (which happens if matrix Y is not distributed).
The "c+d" version copies and distributes.
The "tiled" version is the classic 5 loops algorithm.
The program has been adapted to a run on 3 sizes of the LBP processor: 4 cores (16 harts), 16 cores (64 harts) and 64 cores (256 harts). The matrix size is proportional to the processor size: 16*8*int for matrix X and 8*16*int for matrix Y on a 4 core LBP, 64*32 and 32*64 on a 16 core LBP and 256*128 and 128*256 on a 64 core LBP.
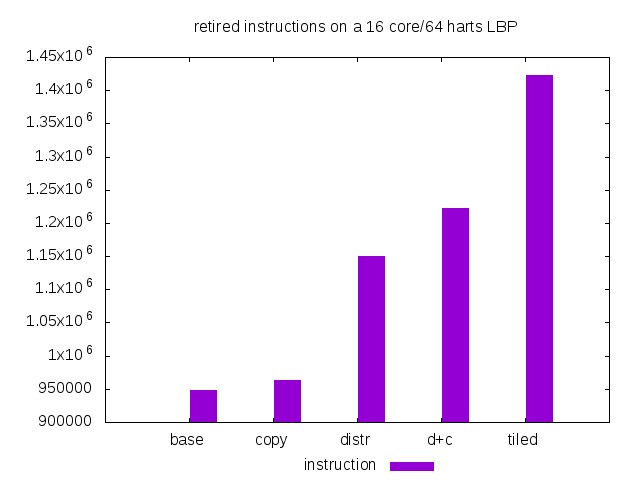
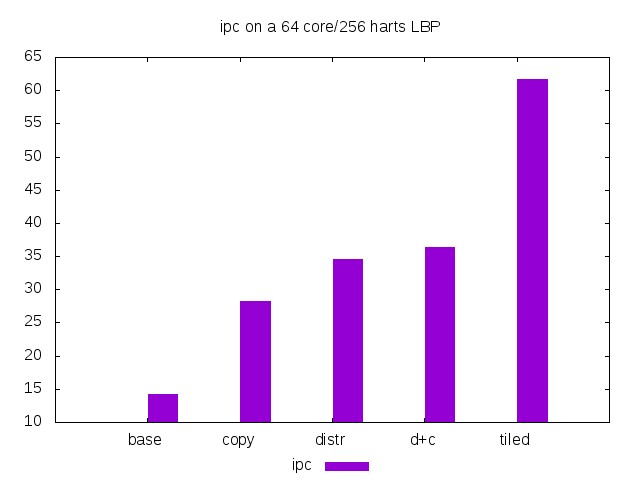
Three sets of three histograms are shown. The first set concerns the ipc (retired instruction per cycle), the second set is the number of cycles and the third set is the number of retired instructions. In each set, we show an histogram of the values for the 4-core, 16-core and 64-core runs. Each histogram presents the evolution according to the five versions of the matrix multiplication program.
The IPC is close to the peak (4 IPC) on 4 cores, whatever the version.
On 16 cores, the IPC is highly increased in the "copy" and the "tiled" versions and slighly drops with the distributed ones. The drop comes from an increase in the number of instructions run as will appear on the "instruction" set of histograms below. Except for the base version, the IPC is close to the peak (16 IPC).
On 64 cores, the IPC is close to the peak for the "tiled" version but only half of the peak for other versions and less than 1/4 of the peak for the "base" version. The loss is due to the simultaneous accesses of the harts to the same memory banks. Even though in the distributed versions the accesses are distributed on the memory banks, there is a concentration effect due to the harts simultaneous accesses to the same portions of the Y matrix. Only the tiled version avoids this concentration. As a rule of thumb, each thread should not emit more than one distant communication request per 16 instructions. In the tiled version, even though the matrices have not been distributed, there is no saturation of the interconnect.


The number of cycles is what really matters. The end user wants his program to run fast (less cycles) rather than fill the cores (high IPC).
On 4 cores, the base version is the fastest. Each enhancement adds instructions which are not enough compensated by the increase of the efficiency.
On 16 cores, the copy version is the best.
On 64 cores, the base version should be avoided. The tiled version is the best choice.



The number of retired instructions impacts the power consumption.
On 4 cores, the base version is the most economic.
On 16 and 64 cores, the copy version is better to mix performance and power efficiency.